Last Updated: 05 Dec 2023
Table of Contents
Synopsis
The Holy Bible is one of the most revered and consistently read texts in the entire world. The complexities of biblical histories, from religious themes and worship, languages, and to major societal events, fascinate scholars today. However, what is commonly overlooked is the connections between the Bible and the Book of Mormon. In the narrative beginning of the Book of Mormon, the record opens with a family commanded by God to leave their home in Jerusalem, escape the impending doom of the Babylonian Exile, and start a new civilization in the modern-day Americas. One of the belongings of this family was a record written on brass plates, which contains the biblical prophets and narratives from the five books of Moses and the words of the Old Testament prophets up to Jeremiah. One of the most commonly referenced authors made by Book of Mormon prophets is Isaiah, in which his words, themes, and doctrines are in 35% of the Book of Mormon.
The prophet Isaiah is heavily revered for Book of Mormon peoples, and their writers and preachers regularly recite from the 66 chapters we have today. However, modern scholars have stated that the authorship of the book of Isaiah is not solely written by the prophet: numerous arguments cirulated stating that Isaiah’s disciples had written chapters 40-66, and Isaiah himself had only contributed chapters 1-39. This claim has validity since the second half is written after the Babylonian Exile (597 to 538 BCE), which was over a hundred years after Isaiah had passed on. The Book of Mormon family left Jerusalem around 600 BCE. This leads to the following question: how could Book of Mormon civilizations have the entire account of Isaiah in the brass plates if the latter half of the Book of Isaiah wasn’t written until after 597 BCE?
Multiple scholarly interpretations have debated these concerns. One assertion is that the book of Isaiah was written wholly by the prophet himself, and disciples later edited it to be in its current format. Others speculate the possibility of divine intervention as the writings of Isaiah and the Book of Mormon went through translations.
My motivation for this project (described both in this blog and the EDA post) is not directed to discuss authorship in great detail, but to illuminate the breadth of Isaiah’s writing using visualization and statistics, accounting for these common scholarly perspectives. I also wish to explore the numerous cross references, subdivisions of Isaiah (using Bernhard Duhm’s classifications), the presence of biblical terms, and textual similarities of words, verses, and chapters between books. This project intends to promote a detailed understanding of the scriptures by visualizing these complexities that would otherwise be incomprehensible.
Data Collection
Finding the right cross reference data was difficult, so I had to pull information from uncanny sources. Data was downloaded and scraped from three locations:
- Linguistics Study in the Book of Mormon
- LDS Documentation Project
- Church of Jesus Christ of Latter-day Saints Bible Dictionary
1. Scraping PDF links for Cross Reference Data
The first location is a static html file that links viewers to numerous pdf files, articles, and websites highlighting differing attributes of LDS doctrine and policy. I was only interested in gathering the data from the KJV_order.pdf, which contains the cross references of all bible verses to all Book of Mormon verses, normally listed as footnotes in the Latter-day Saint version of the KJV Bible. Since this was a pdf file listed on the main site, I wanted to extract the website links using webscraping and download the pdf of interest in Python:
# Import libraries
import pandas as pd
import requests
from bs4 import BeautifulSoup
import pdfplumber
import re
# for link in links:
# print(link.get('href'))
# I want http://www.creationismonline.com/Mormons/KJV_Order.pdf and to download it for pdf scraping, so I will access it as so:
local_file_path = "../DirtyData/cross_reference.pdf"
cr_link = requests.get(links[9].get('href'))
with open(local_file_path, "wb") as pdf_file:
pdf_file.write(cr_link.content)
My newly downloaded pdf file was then extracted using pdfplumber. I filtered the lines to extract only those that had “Isaiah” in the row and appended it to vector cr.
cr = []
with pdfplumber.open(local_file_path) as pdf:
for page in pdf.pages:
pdf_text = page.extract_text()
lines = pdf_text.split('\n')
for line in lines:
if "Isaiah" in line:
cr.append(line)
Now instead of a vector of strings, I want to write a dataframe cr2 that has two columns: one for the Isaiah chapter, and one for the Book of Mormon chapter. However, this extracted the entire line of text instead of the two columns. I will need to set up a new dataframe and write two new ‘for’ loops that first, limits the data into two columns and second, cleans the string objects.
# setting up dataframes
cr2 = pd.DataFrame()
cr2['Isaiah_chapter'] = []
cr2['BoM_chapter'] = []
# 1: turning four column table into two columns
for row in cr:
parts = row.split()
if "Isaiah" in parts[0]:
new_row = {'Isaiah_chapter': parts[0], 'BoM_chapter': parts[1]}
cr2.loc[len(cr2)] = new_row
if "Isaiah" in parts[2]:
new_row = {'Isaiah_chapter': parts[2], 'BoM_chapter': parts[3]}
cr2.loc[len(cr2)] = new_row
# 2: cleaning string values (separates numbers from name)
cr2['Isaiah_chapter'] = cr2['Isaiah_chapter'].str.replace(r'(\d+)', r' \1', 1)
nrs = []
for row in cr2['BoM_chapter']:
if "Nephi" in row:
nr = re.sub(r'(\d)Nephi', r'\1 Nephi', row)
nr = re.sub(r'(\d+)', r' \1', nr, 2)
nr = re.sub(' ', '', nr, 1)
nrs.append(nr)
else:
nr = re.sub(r'(\d+)', r' \1', row, 1)
nrs.append(nr)
cr2['BoM_chapter'] = nrs
Then I export my simple cross reference data to a csv file using cr2.to_csv(file_path).
2. Downloading Textual Data from the LDS Documentation Project
Thanks to the LDS Documentation Project for their Mormon Documentation Repository for providing an extensive list of the book title, chapter number, verse number, and verse text for every single LDS scripture, This allowed the pairing of sciptural text between Isaiah and the Book of Mormon to be a very feasible process. More on this process in Data Processing
3. Scraping Bible Dictionary Terms from churchofjesuschrist.org
In my third dataset, I scraped the list of words from the LDS Bible Dictionary. Using Python to extract the words was a much more intuitive process. In simple terms, I initialized a new vector, scraped each word using Python’s BeautifulSoup, and appended the cleaned text to the vector. The vector was then rewritten as a one-column dataframe titled bd_df and written using bd_df.to_csv(file_path).
# webscraping from LDS bible dictionary terms
bd_df = []
bd_url = 'https://www.churchofjesuschrist.org/study/scriptures/bd?lang=eng'
r2 = requests.get(bd_url)
soup = BeautifulSoup(r2.text, 'html.parser')
bd_terms = soup.find_all(class_ = 'title')
bd_terms = bd_terms[2:]
for term in bd_terms:
bd_df.append(term.text)
bd_df = pd.DataFrame(bd_df)
bd_df.columns = ["Term"]
This bible dictionary dataset will be used after our cross reference data is prepped.
Data Processing
Now that we have a dual-column dataset that lays out the cross references between Isaiah and the Book of Mormon, now we need to use our comprehensive scripture dataset to add the ID variables (book, chapter, verse) and the verse’s text to expand the cross references.
I accomplished my goal to merge the data into three steps:
1. Filter the scripture dataset to include only Isaiah and the Book of Mormon
Using pandas, I coded the data downloaded from the LDS Documentation Project and filtered it to only contain verses from Isaiah and the Book of Mormon. These are the only books we care about.
2. Take the scripture data and structure it like the cross reference data
I took the filtered scripture data and merged it twice, the first time to the Isaiah chapter column, and the second time to the Book of Mormon chapter column. I also dropped some redundant columns and added suffixes to the variables of the same name. This will help me specify which verse and chapter is the scripture.
# Merge references with scripture texts
ISH = pd.merge(filtered_scripts[filtered_scripts['book_title'] == "Isaiah"], cr, how = 'left', left_on='verse_title' right_on='Isaiah_chapter')
full_cr = pd.merge(ISH, filtered_scripts, how = 'left', left_on='BoM_chapter', right_on='verse_title', suffixes=['_ISH','_BOM'])
full_cr = full_cr.drop(['Isaiah_chapter','BoM_chapter'], axis = 1)
3. Add in Book of Mormon text that was not cross referenced
Finally, I wanted the data to be fully comprehensive, meaning that all verse data for the Book of Mormon and Isaiah are included. So, I joined all the Book of Mormon verses that weren’t directly referenced into the data.
The final output looks something like this.
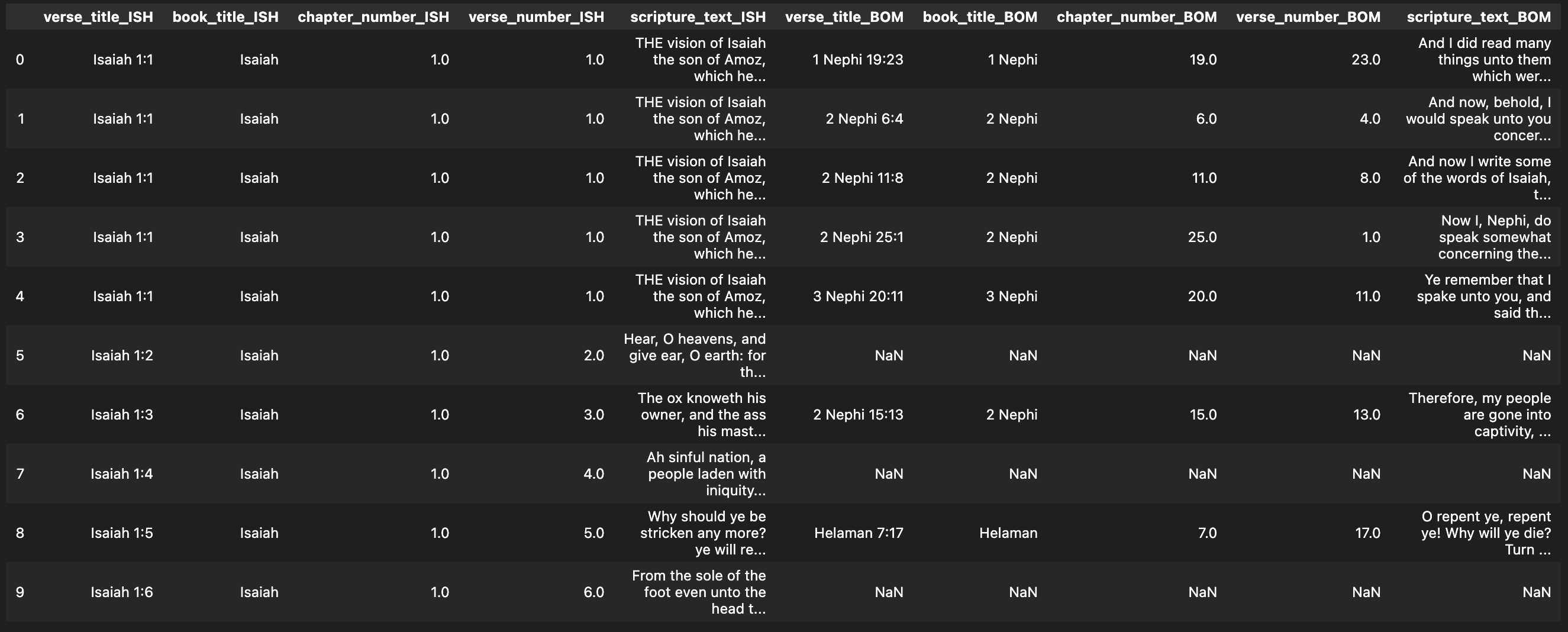
However, I am still missing some very important information that wasn’t available from the web.
Data Building
The next step requires some extensive web exploration to formulate relevant variables; our data contains identification variables and the verse text, but it is missing information that can answer the research questions. I want the data to contain a text language similarity score for each reference, a TRUE/FALSE detection for biblical terms within the verse (and the term itself), a classification on Isaiah’s narrative structure (Duhm’s classifications).
1. Evaluate text similarities between verses
Python libraries nltk and textdistance provide great resources to be able to process and compare text. Since my dataframe is already organized in a way that it knows which verse in Isaiah cross references the verse in the Book of Mormon, a simple for loop can run through each row and compare the text.
I used nltk stopwords to remove certain filler words like ‘I’,’and’, or ‘to’ from the text, and textdistance to calculate text similarities between the remaining words. I went with the cosine method to calculate similarity scores as it is generally preferred when working with text. You can also learn more on text language processing
# calculating similarities between words in verses
cosine_sim_dist = textdistance.cosine(ISH_words, BOM_words)
Cosine similarity is a method of comparing text based on the frequency of identical words used between different texts. In this case, I used this method to compare two verses from each other. A similarity score ranges from 0 to 1, where the highest score indicates very alike texts. The formula for finding the similarity score is based on how linear algebra students calculate the angle between two vectors, as the cosine of the angle is calculated as follows:
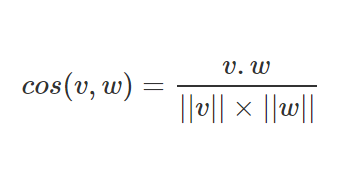
As an example, say verse v is written “the Lord loves His children”, and verse w says “God loves His children.” Removing the stopwords would give us one account of each word ‘loves’, ‘His’, and ‘children.’ However, ‘Lord’ and ‘God’ would differ. That means both verses v and w are vectors with five binary elements (i.e. 1s and 0s). Computing v and w using the equation above would procure a cosine similarity score of .75.
The similarity scores were then classified to simplify the verse into a type of reference.
- Direct Quote = .75 to 1
- Shared Language = .25 to .75
- Similar Theme = 0 to .25
2. Detect if verse contains a bible term and list it
Now it is time to find where biblical themes occur throughout both authors. Using the LDS Bible Dictionary, I created a lemmatizer from nltk and ran through each verse to detect a bible dictionary term. A lemmatizer is a tool that, in simple terms, detects multiple forms a word can take, such as the word ‘idol’, which may be referenced as ‘idols’ or ‘idolatry’. More about lemmatizers can be found here. I also created a column in the data that not only determined whether a bible dictionary term was found, but what the first detected bible dictionary term was.
# initialize vectors
bd_found = []
bd_list = []
# initialize the lemmatizer
lemmatizer = WordNetLemmatizer()
# run through each verse
for verse in full_cr['scripture_text_ISH']:
verse_words = verse.split()
found_word = False
for word in verse_words:
lemma = lemmatizer.lemmatize(word, 'n')
if lemma in bd['term'].values:
bd_list.append(lemma)
found_word = True
break
if found_word:
bd_found.append(True)
else:
bd_found.append(False)
bd_list.append('')
3. Categorize Isaiah using Duhm’s classifications for the chapters
Bernhard Duhm uses varying structures and models to break up and explain the chronological and thematic differences in Isaiah. In this project, we used the threefold structure to identify them:
- Proto-Isaiah lists chapters 1-39 (742-687 BCE). It encompasses the stories and words of Isaiah in 8th-century BCE, where he narrates certain events like his call to prophethood, the Syro-Ephramite war, and the rise of the rightoeus king Hezekiah.
- Deutero-Isaiah lists chapters 40-55 (597-538 BCE). This is believed to originate from the work of an anonymous 6th-century acolyte of Isaiah, written during the time of the Babylonian exile.
- Trito-Isaiah lists chapters 56-66 (after 538 BCE). This was mainly composed after the Exile and the Jews’ return to Jerusalem.
Retrieving this variable and incorprating it into the data was very simple. All it took was a function that looked into the chapter number and assigned the Duhm classification to the row in the data.
Final Output
After building the ascribed variables to analyze scripture data in greater detail, the dataset looks as follows:
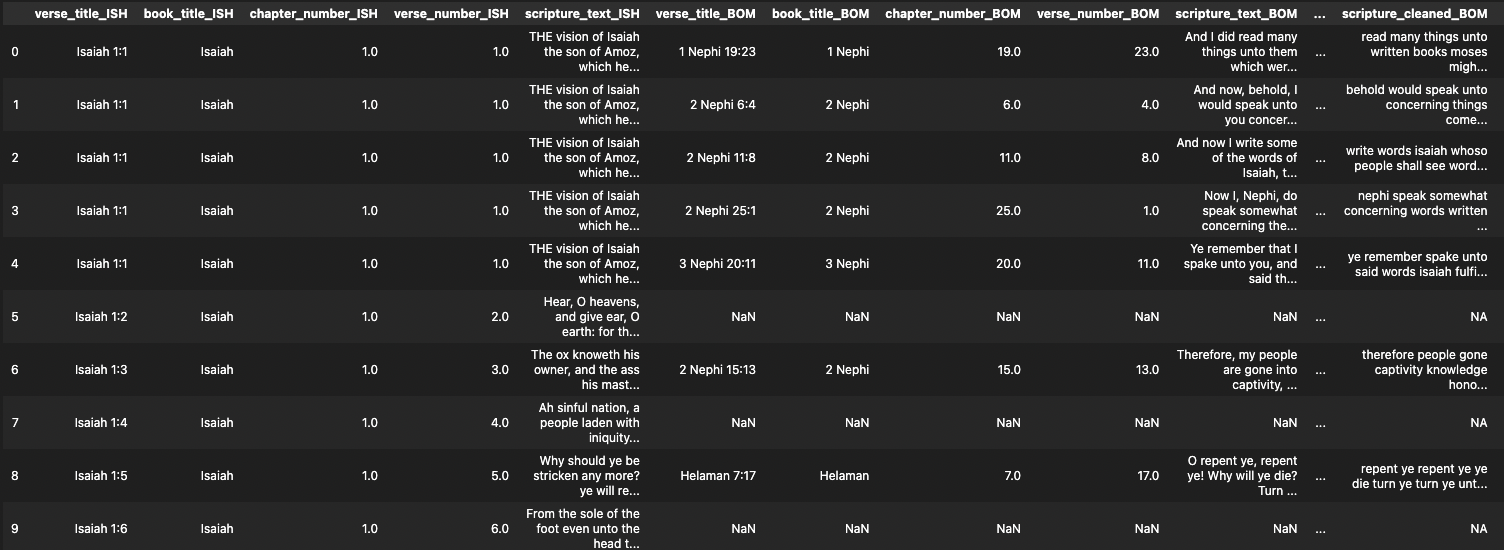
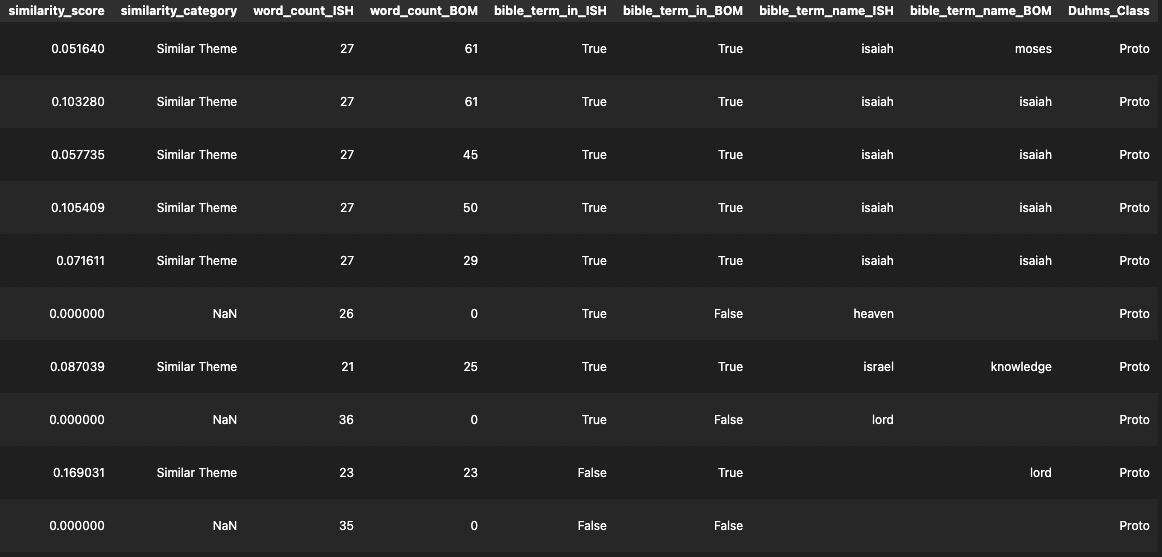
If you want to learn more about the details on how I accomplished building the data, you can check out my repository. You can also download the spreadsheet of the cross reference verse data from GitHub.
Conclusion
The preparation involved for constructing this dataset is extensive and carefully completed, such that scriptural information is not misrepresented or misinterpreted. I expanded my research outlook by consulting other resources where I can better relate Isaiah to the Book of Mormon.
There are four areas whereby we can center our exploration:
- Where in Isaiah does the Book of Mormon most refer to?
- Where in the Book of Mormon is Isaiah heavily referenced?
- How much is biblical language utilized in Isaiah and the Book of Mormon?
- Where do textual differences occur between Duhm’s Classifications and the Book of Mormon?
I answer these questions in my next blog post Exploring Isaiah’s Legacy in the Book of Mormon - EDA and Dashboard.
Acknowledgements and Ethical Considerations
All data used was made publicly available. The inspiration for this project came from the OpenBible.info and Medium. Part of the data was downloaded from the LDS Documentation Project, a research organization providing public domain data files on LDS scriptures. Rest of the raw data was scraped from Linguistics Study in the Book of Mormon and The Church of Jesus Christ of Latter-day Saints. I am grateful for these sources and their openness to provide available data for me to complete this project.